
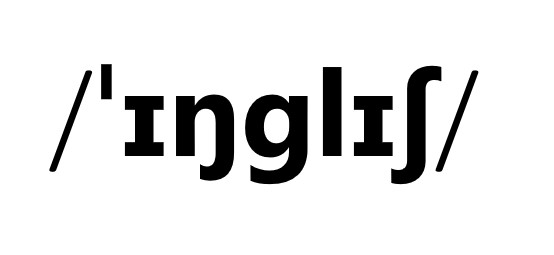
The consonants of English vary in their complexity and in their distinguishing pronunciation features. After understanding the basics of the simplest English consonants, there are a few more things that determine how a speaker can sound more like a native speaker or at least comprehend some of the strange sounds native speakers make, especially when speaking quickly or colloquially, for example in television comedies. Some of those features are explained here.
Along with voice, aspiration is one of the most obvious features of English consonants. This is the amount of air released in the final phase of pronunciation of stops or plosives. English consonants are distinguished by aspiration and called either lenis (soft) or fortis (strong) depending on how much air is released in this phase. While aspiration is not really connected to voice, in English the lenis consonants tend to be voiced, and the fortis unvoiced.
A consonant is not necessarily always one or the other, though, as the environment in which a sound is found may affect how much air is released. A /p/ at the beginning of a word like pie has less aspiration, for example, as the force of articulation is transformed into the enunciation of the following vowel sounds. Following /s/ will also lead to less aspiration, perhaps because much of the air has been released during the production of the continuant: hear spy. Word-final fortis consonants will have more aspiration, particularly if they are followed by vowel sounds in the following word (rap on) but less so if a nasal (rap music), a similar sound (rap beat), or a voiced consonant (wrap that) follows. Finally, such consonants will have the greatest force of articulation if they are right at the end of a sentence or exclamation: Help!
A significant phonological phenomenon in English is the effect of lenis consonant endings on the vowels preceding them. Try reading these minimal pairs aloud and see if you can hear/feel what is different besides the sound of the consonant.
| bat | bad |
| rack | rag |
| batch | badge |
| half | have |
Now listen:
The final consonants sounds on the right are voiced at least partially (they start out voiced and then tend to become voiceless unless a voiced sound follows) and have little or no aspiration. They are lenis consonants (vs fortis consonants in the left-hand column).
Words like those in the right-handed column may be problematic for German speakers because German tends to have only fortis final plosives, fricatives, affricates.
Additionally, the vowels in these words on the right are longer than those in the left-handed column. The lenis consonants at the end of syllables sort of stretch out the vowels preceding them, causing those to lengthen. Often a listener understands the speaker not through the distinction between consonants (which in fact can be distorted by environment, technology and the like), but in fact thanks to the difference in the vowel. This makes this feature of English quite important for intelligibility as well as something quite specifically English.
Suffix pronunciation
The environment of a sound can also affect it in other ways. This is particularly noticeable in English suffixes. How the plural -s or the past tense -ed is pronounced is very flexible based on the sound preceding. Thus, cap /kaep/ is pluralized as caps /kaeps/ or put into the past tense as capped /kaept/, while the same suffixes sound different on cab /kaeb/: cabs /kaebz/ and cabbed /kaebd/. You can see (or, rather, hear), that the voice of the preceding consonant affects whether the suffix is also voiced or not: voiceless /p/ leads to voiceless /s/ and /t/, and voiced /b/ to voiced /z/ and /d/. Finally, sibilant consonants will mean that the e is pronounced in plurals, e.g. kiss -> kisses: /kɪs/ -> /kɪsᵻz/ ; also, the alveolar plosives d and t will have the same effect in past tense forms: flood -> flooded becomes /flʌd/ -> /flʌdᵻd/ . Try this exercise to see how many you get right.
The Standard American voiced alveolar tap
An additional important consonant which is heavily affected by its environment is the USAmerican voiced alveolar tap /ɾ/. In spite of all the patterns described above, Standard American English is characterized by this intervocalic voicing of t or tt to sound like /d/, or rather /ɾ/: Hit it! is /hiɾiɾ/, letter is /leɾer/, etc. The voiced alveolar tap sounds much like the voiced plosive /d/ and some linguists do not distinguish between them. It is something that will definitely mark a speaker as non-American, and could also lead to misunderstandings if you don’t know what you are hearing, so it is important to be aware of it. The voiced alveolar tap occurs:
- between vowels both within and across words: matter, sit up
- at the beginnings of suffixes: fifty, writing, accepted
- following /r/ or /l/: party, filter
but never at the beginnings of stressed syllables:
| attention | IPA: attention əˈtɛn ʃən |
| particular | IPA: particular |
| alternative | IPA: alternative |
So there are number of ways in which what look like simple combinations of sounds become more complex. With these exercises you can test your understanding of the basic ideas, but also practice your listening comprehension and eventually your own pronunciation.
